
شبیه سازی صدا در 3 ثانیه با کمک هوش مصنوعی جدید مایکروسافت VALL-E
پنجشنبه گذشته محققان مایکروسافت یک مدل جدید هوش مصنوعی تبدیل متن به گفتار که به راحتی در سه ثانیه میتواند این وظیفه را انجام دهد با نام VALL-E معرفی کردند.

به گزارش گروه دانش و فناوری اقتصاد ۱۰۰ و به نقل ازسخت افزارمگ ،این الگوریتم هوش مصنوعی زمانی که یک صدای خاص را یاد گرفت میتواند به راحتی با حفظ لحن، صحبتهای گوینده را تکرار کند.
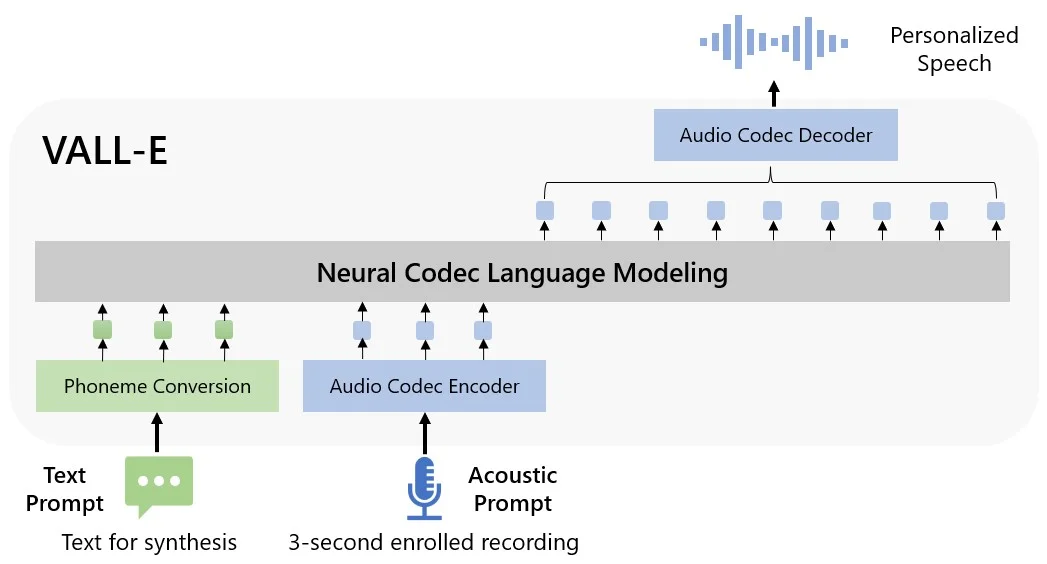
سازندگان این AI تخمین زدهاند که VALL-E میتواند برای اپلیکیشنهای تبدیل متن به گفتار با کیفیت و ویرایش صوتی گفتار مورد استفاده قرار گیرد. مایکروسافت VALL-E را مدل کدک عصبی زبانی توصیف کرده و اعلام کرده که این فناوری با کمک تکنولوژی به نام EnCodec که متا در اکتبر 2022 معرفی کرده ساخته شده است.
برخلاف سایر روشهای تبدیل متن به گفتار که معمولا با دستکاری شکل موج به وقوع میپیوندد، مایکروسافت اظهار کرده که VALL-E کدکهای صوتی مجزا و اختصاصی را بر اساس متن و پیام صوتی به صورت مستقل تولید میکند و اساساً صدای یک شخص را تحلیل میکند و آن را به کمک EnCodec به اجزای اختصاصی تبدیل میکنند و با استفاده از الگوریتمهای یادگیری ماشین و دیتای آموزشی، چگونگی بیان دیگر جملات و کلمات را با همان صدای صوتی تحلیل و پیش بینی میکند.
ردموندیها قابلیت تمرین گفتار هوش مصنوعی VALL-E را مبتنی بر لایبرری نرمافزاری LibriLight که توسط متا توسعه یافته خوانده که شامل 60,000 ساعت سخنرانی به زبان انگلیسی بیش از 7000 سخنران است و عمدتاً از کتابخانه صوتی LibriVox استخراج شده است.
Microsoft همچنین در وبسایت VALL-E نمونههای عملی از مدل گیری این هوش مصنوعی را به اشتراک گذاشته است. این تکنولوژی با وجود مفید بودن و ارائه قابلیتهای کاربردی، توانایی جعل صدا برای استفادههای غیرقانونی خصوصاً در شبکههای اجتماعی را نیز دارد و مایکروسافت با آگاهی از این مورد VALL-E را به صورت مستقیم و مستقل برای آزمایش در دسترس قرار نداده است.
