

هوش مصنوعی متا در دو هفته ساختار سهبعدی 600 میلیون پروتئین را به دست آورد
محققان متا سیستمی مبتنی بر هوش مصنوعی ساختهاند که میتواند دنبالههای ساختاری پروتئینهای موجودات زنده را به خوبی پیشبینی کند.
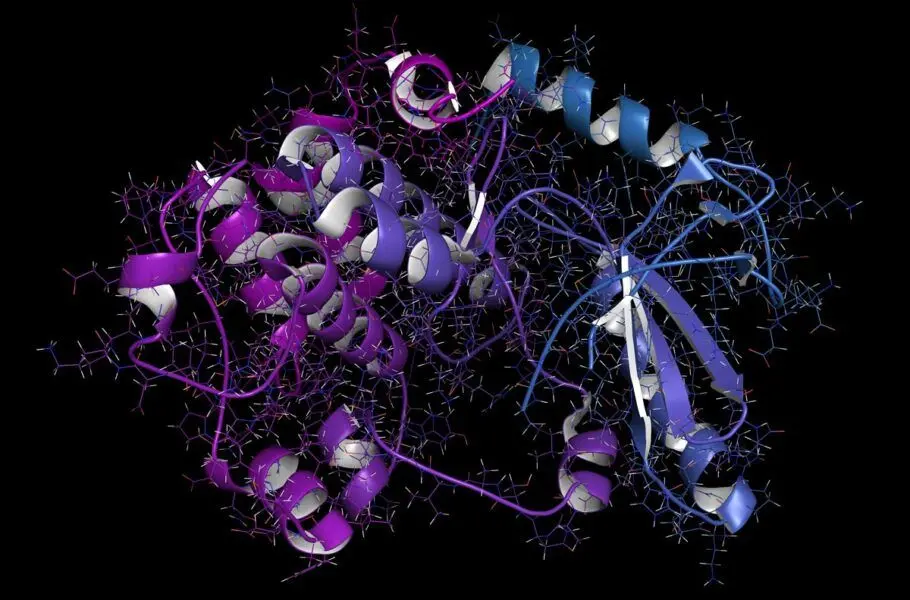
به گزارش گروه دانش و فناوری اقتصاد ۱۰۰ و به نقل از دیجیاتو، دانشمندان شرکت متا، کمپانی مادر فیسبوک و اینستاگرام با استفاده از یک مدل زبانی هوش مصنوعی موفق به پیشبینی ساختار بیش از 600 میلیون پروتئین در دو هفته شدند. این پروتئینها متعلق به ویروسها، باکتریها و میکروبها بودند و حالا میتوان حتی از این اطلاعات در تولید داروهای جدید استفاده کرد.
برنامهای موسوم به ESMFold در متا وجود دارد که در ابتدا برای رمزگشایی از زبانهای انسانی طراحی شده بود. حالا دانشمندان از این برنامه استفاده کردهاند تا پیشبینیهای دقیقی درباره پیچیدگی ساختارهای سهبعدی پروتئینها داشته باشند. از این پیشبینیها که بهصورت متن باز در اطلس ESM Metagenomic منتشر شده، میتوان برای تولید داروهای جدید، تشخیص کارکردهای ناشناخته میکروبی و ردیابی ارتباطات مهم میان گونههای همخانواده با نسبت دور استفاده کرد.
ESMFold اولین مدل هوش مصنوعی برای پیشبینی پروتئینها نیست. دیپمایند گوگل هم در سال 2022 از مدل مشابهی به نام AlphaFold برای همین منظور رونمایی کرد. ولی متا مدعی است که سیستم آنها 60 برابر سریعتر از سیستم دیپمایند است. نتایج مطالعات متا بهصورت پیشچاپ در پایگاه داده bioRxiv منتشر شده است.
استفاده از مدل هوش مصنوعی زبانی متا برای پروتئینها
پروتئینها بلوکهای سازنده تمام موجودات زنده هستند و از زنجیرههای بلند آمینو اسیدها ساخته شدهاند. آگاهی از شکل پروتئینها بهترین راه برای اطلاع از کارکرد آنهاست، اما آمینو اسیدها به روشهای بسیار زیادی میتوانند شکل بگیرند و پروتئینها را بسازند. بهترین روش برای تعیین ساختار یک پروتئین استفاده از «بلورنگاری پرتو ایکس» است، یعنی ببینیم نور پرانرژی چگونه در پروتئینهای مختلف شکسته میشود، اما اجرای این روش طاقتفرسا میتواند ماهها یا سالها طول بکشد و روی همه پروتئینها جواب نمیدهد.
در نتیجه، محققان متا مدل کامپیوتری پیشرفتهای ساختهاند که سعی میکند زبان دنبالههای پروتئینی را بفهمد. این مدل با دنبالههای میلیونها پروتئین طبیعی آموزش داده شده و میتواند بهصورت خودکار جاهای خالی را در دنبالهها پر کند.
آنها برای آزمایش این مدل به سراغ یک پایگاه داده متاژنومیک DNA از مکانهای مختلفی مثل خاک، آب دریا و روده انسان رفتند و این اطلاعات را به ESMFold دادند. پژوهشگران در پایان کار در عرض دو هفته توانستند ساختار بیش از 617 میلیون پروتئین را پیشبینی کنند. این رقم در بازه زمانی مشابه حدود 400 میلیون بیشتر از AlphaFold است.
دانشمندان باور دارند که بیش از 200 میلیون پیشبینی با ESMFold با کیفیت بالا بوده است. آنها حالا امیدوارند که از این سیستم برای کارهای بیشتری در زمینه پروتئینها، سلامت، بیماریها و محیط زیست استفاده کنند.
